Project 1: Benty-fields publication prediction engine
On benty-fields we train a machine learning model to (1) order your daily list of publications and (2) make paper recommendations shown on the main page www.benty-fields.com. Currently, we train a separate model for each user. The model provides a probability value for any paper, representing whether the user might be interested in this paper or not. Here we will show you what model we use and we want to challenge you to come up with a better approach.
First, what training data do we have? Benty-fields users can show interest in papers by (1) voting, (2) adding papers to their library, and (3) using the thumbs up button. We provide the list of papers associated with 1402 anonymized users of benty-fields (these are users with more than 40 data points/papers available).
We provide a list of arXiv ids for each user. Using the arXiv API (https://arxiv.org/help/api) you can get heaps of metadata for these papers (anything you think might be useful to train your model). If you don't want to use the arXiv API, we also provide (1) a list of abstracts, (2) a list of paper titles, and (3) a list of authors for each paper. At benty-fields we are currently only working with the abstract, title, and author list to train our model. You can get the data here (332Mb).
Note that for each user we provide 50% positive papers (papers the user has shown interest in) and 50% negative papers (papers the user has not shown any interest in). The negative papers are randomly selected from the arXiv categories the user has subscribed to. You can separate the positive and negative papers using the file name y_#. The rows indicate positive papers with 1 and negative papers with 0.
There are two metrics you can use to evaluate your model and compare with ours, precision and AUC (AUC = Area under the receiver operating characteristic curve). Our results for all 1402 users can be found here (precision) and here (AUC). The AUC result is plotted below.
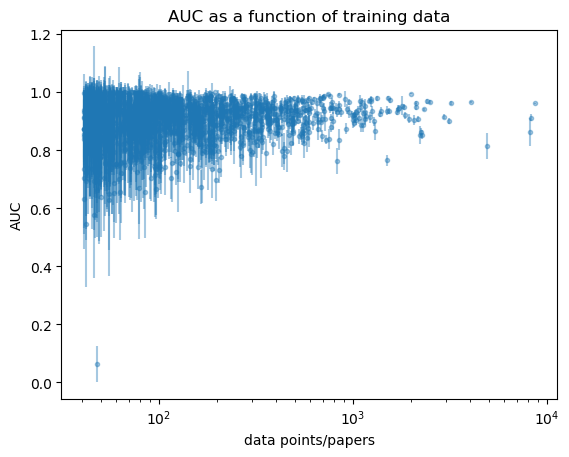
The code for the model used in benty-fields can be found at github. Our model uses natural language processing (NLP) and term-frequency inverse document-frequency features together with a random forest classifier. By running the function test_paper_recommendation_engine() you can produce the AUC and precision data provided above. By replacing _get_model_metrics_through_cross_validation() you can calculate the same metrics with your model and compare with our results.
We are interested to see whether you can provide a model, which performs better than our model. Note, however, that we can't promise that we will adopt your solution. It also depends on factors like computation time, resources, etc.
Past work
Alexander Thomson-StrongSummer project 2021, University of Edinburgh
Summary: The model above can be improved by using an Extra trees classifier rather than random forest.
Download Report
Project 2: Extracting citation information for arXiv papers
We would like to have a citation graph for all arXiv papers. For each arXiv paper, this graph should provide a list of references representing the full bibliography. The distance between papers in such a citation graph contains valuable information, which could be used for the paper recommendations engine on benty-fields.com. This project mainly aims to develop techniques to extract information about citations from arXiv papers.
The main difficulty here is to develop reliable techniques to detect citations. Most arXiv papers come in the form of .tex files, which contain a bibliography using the \bibitem{} tag. We already wrote some code that,
(1) downloads all available files of a paper from arXiv,
(2) extracts the \bibitem{} tags and
(3) searches for arXiv ids and digital object identifier (doi) using regular expressions.
You can download this code here. The regular expressions we implemented so far can only detect a small subset of the available citations. The open question is, how one can reliably extract citations, given the fairly unpredictable citation formats used in academic papers. In particular we are looking for machine learning solutions, which can process the text within a reference and automatically detect the title, author list, journal reference etc.
We are interested to see whether you can provide some code, which can (reliably) return the list of arXiv ids (or dois) representing the bibliography for any given arXiv paper. We are interested to deploy such a feature on benty-fields.com.
Past work

Matej Vedak
Summer project 2022, University of Edinburgh
Summary: Our goal was to create a python script that would detect references in papers and extract data about them - linking the references to the paper they were found in. References are identified primarily either through arXiv IDs or DOIs (digital object identifiers). References that have neither of those things are sent to a special online service called Crossref, which matches the sent reference to a scientific paper in its database. Data that is gathered about these references is saved in a database, so it can be retrieved quickly and on-demand.
Download Report
Download Poster
Project 3: Most popular papers
For users which currently don't have any training data available, we don't order the daily new papers, but rather use a random order. Following project 1 we could instead order the papers according to their correlation with the most popular papers in the past weeks or months.
Here we provide the list of arxiv ids for the most popular papers of the past 12 months (from 14/09/2021). We use the number of journal club votes as a measure for popularity and we provide the number of votes for each paper as well as its primary arxiv category (download here). As mentioned in project 1, you can use the arXiv API (https://arxiv.org/help/api) to get additional data for each of these papers.
Parts of the code provided in project 1 might be quite helpful for this project.
We are interested to see whether you can provide a model, which can predict papers that will be more popular than others. If yes, we would like to use this code to order papers for users without enough training data to train their own model.
Your help with developing benty-fields.com is very much appreciated. In the case we adopt any code you developed, you will be credited on the About page of benty-fields.com and you will receive all the fame and glory associated with that  .
.
For any inquiries just get in touch with us.